Snowflake SQL Window Functions and Common Errors
- How-Tos FAQs
- August 20, 2020

Snowflake SQL Window Functions and Common Errors
Most database users have expertise in using the standard aggregate functions, such as SUM, MIN, MAX, COUNT, etc. These aggregate functions parse the entire table and return a single record. Typically you use these with a group-by clause. Furthermore, the group-by clause slices the dataset into groups based on the columns provided to the clause. What are some Snowflake SQL Window Functions and Common Errors?
On the other hand, you can use window functions to parse a set of rows to return an aggregated value for each row in that “window.” The window could be the entire dataset or typically a subset of the dataset. Furthermore, window functions do not slice the dataset.
Basic Syntax:
{WINDOW_FUNCTION ([ALL] expression) OVER ([PARTITION BY list_of_columns] [ORDER BY order_list])Understanding the syntax:
{WINDOW_FUNCTION:
Aggregate Functions: SUM, MIN, MAX
Rank Functions: RANK, DENSE_RANK, ROW_NUMBER, NTILE
Value Functions: LEAD, LAG, FIRST_VALUE, LAST_VALUE
ALL: Optional keyword to include all the columns and their values. Please note, Window functions do not support the DISTINCT keyword.
expression: The target column on which the function runs
OVER: contains the clauses to be applied to the “window”
PARTITION BY: This optional keyword helps to form the “size of the window.” Without this, the window function will run on the entire dataset.
ORDER BY: This optional keyword helps to sort the records within partition/windowLet’s create some sample data within our Snowflake instance.
{CREATE OR REPLACE DATABASE TEST_1;
USE DATABASE TEST_1;
USE SCHEMA PUBLIC;First, we must create a test database “TEST_1”, and within it, we will use the “PUBLIC” schema to create our table.
{CREATE OR REPLACE TABLE ORDERS
(
id NUMBER,
date DATE,
customer_name STRING,
city STRING,
amount NUMBER(10, 2)
);Create a simple “ORDERS” table with the five columns mentioned above in the PUBLIC schema.
{INSERT INTO orders
SELECT 1,'08/01/2021','Mike Engeseth','Austin',10000
UNION ALL
SELECT 2,'08/02/2021','Mike Jones','Dallas',20000
UNION ALL
SELECT 3,'08/03/2021','John Engeseth','Boston',5000
UNION ALL
SELECT 4,'08/04/2021','Michael Engeseth','Austin',15000
UNION ALL
SELECT 5,'08/05/2021','Mike Coulthard','Boston',7000
UNION ALL
SELECT 6,'08/06/2021','Paul Engeseth','Austin',25000
UNION ALL
SELECT 7,'08/10/2021','Andrew Engeseth','Dallas',15000
UNION ALL
SELECT 8,'08/11/2021','Mike Shelby','Dallas',2000
UNION ALL
SELECT 9,'08/20/2021','Robert Engeseth','Boston',1000
UNION ALL
SELECT 10,'08/25/2021','Peter Engeseth','Austin',500
;Let’s load ten records into our table.
{SELECT * FROM orders;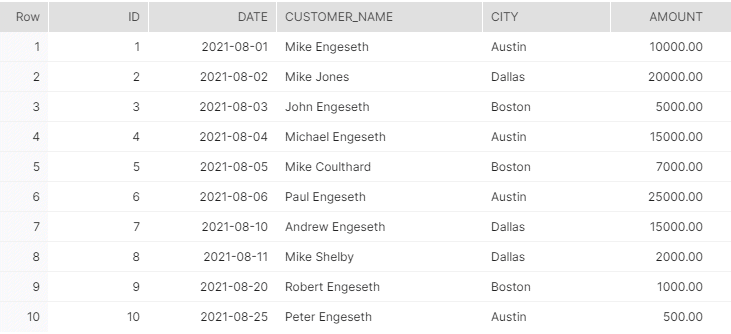
Finally, that is how your dataset should look like.
Let’s look at some examples of Window Functions:
MIN()
The MIN() aggregate function searches for the minimum value in a subset of records or “window” (or entire table).
Using the syntax we learned earlier:
{SELECT id, date, customer_name, city, amount,
MIN(amount) OVER(PARTITION BY city) as minimum_amount
FROM orders
ORDER BY city;Please note, your worksheet context has to be within the PUBLIC schema of the TEST_1 database. This query creates a “window”/subset of records by city, using the partition by keywords.
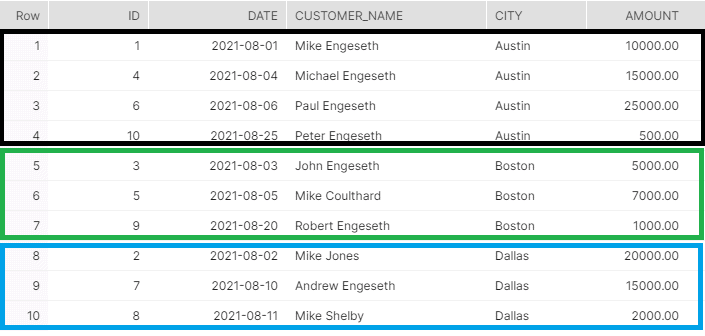
The image just above depicts how each partition/subset/window would look.
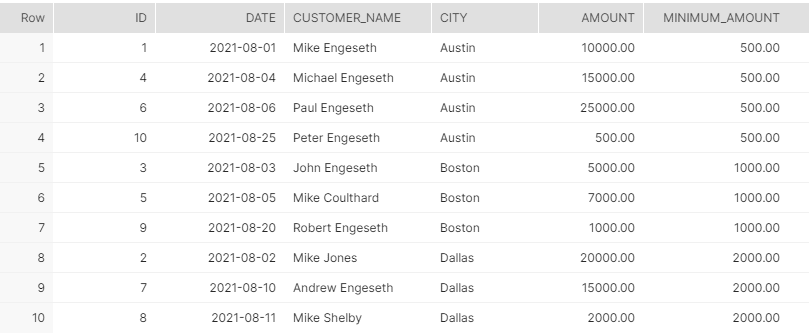
The above image is what the final data set looks like. As you can see, a new column is added, “MINIMUM_AMOUNT” (Snowflake ignores lower-case), which shows the minimum amount from each city, e.g., Austin’s minimum amount is 500.00.
Similarly, if you change the above script to use the MAX function instead, you would get a new column depicting the maximum amount by city, e.g., Boston’s maximum amount is 7000.00.
RANK
The Ranking window function “RANK” calculates the rank of all/subset of records in a specified field.
Using the syntax we learned earlier:
{SELECT id, date, customer_name, city, amount,
RANK() OVER(ORDER BY amount DESC) as amount_rank
FROM orders;![]()
The above image is what the final data set looks like. As you can see, a new column has been added, “AMOUNT_RANK” (Snowflake ignores lower-case), which shows the rank of each of the amounts in our dataset.
Interestingly, two ids [4, 7] have the same amount and rank of 15000.00 and 3 respectively. Moreover, we skipped rank four, and the next rank is 5.
This is required in some use-cases, but in others, we’d like our ranking system not to skip the fourth rank.
DENSE_RANK
The dense rank is identical to the rank function, except it does not skip a rank after a duplicate rank.
Using the syntax we learned earlier:
{SELECT id, date, customer_name, city, amount,
DENSE_RANK() OVER(ORDER BY amount DESC) as amount_dense_rank
FROM orders;![]()
The above image is what the final data set looks like. As you can see, a new column has been added, “AMOUNT_DENSE_RANK” (Snowflake ignores lower-case), which shows the rank of each of the amounts in our dataset.
Interestingly, two ids [4, 7] have the same amount and rank of 15000.00 and 3 respectively. However, this time, rank four has NOT been skipped, and the next rank is 4.
LAG
Lag is a powerful “value” window function that accesses the data from the previous row in the same result set without using joins.
Using the syntax we learned earlier:
{SELECT id, customer_name, city, amount, date,
LAG(date, 1) OVER(ORDER BY date) as prev_date
FROM orders;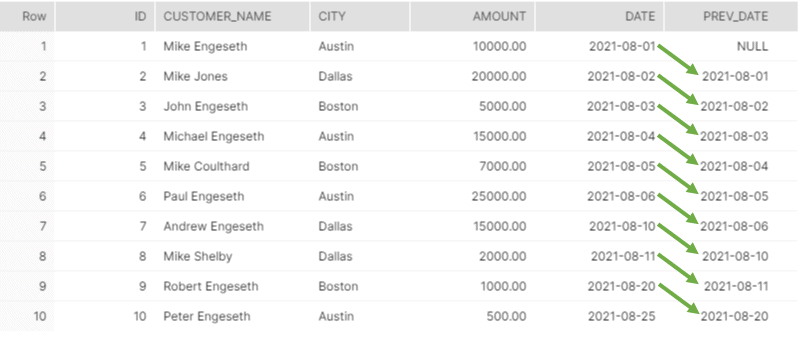
In this use case, we’re taking the date from the previous record and printing it in a new column “PREV_DATE” (Snowflake ignores lower-case). A typical use-case for doing this is when you want to compare current and previous year taxes paid. Or bonuses paid out to your employees in the current and previous years.
It is important to note that the first record in the “PREV_DATE” LAG column will always be NULL, as there are no records in the previous year/record.
LEAD
Similarly, the Lead function is also mighty in that it retrieves the data from the next row in the same result set without using joins.
Using the syntax, we learned earlier:
{SELECT id, customer_name, city, amount, date,
LEAD(date, 1) OVER(ORDER BY date) as next_date
FROM orders;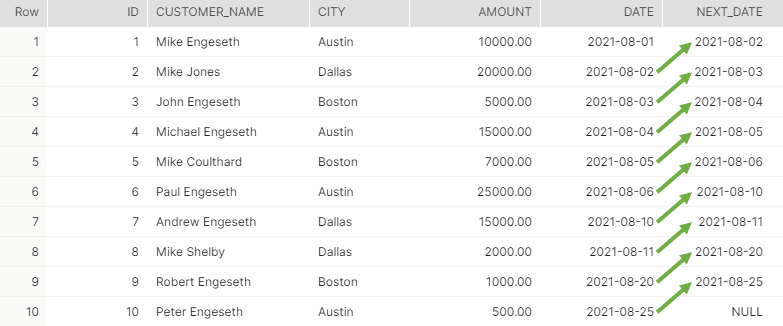
In this use-case, we’re taking the date from the next record and printing it in a new column “NEXT_DATE” (Snowflake ignores lower-case). A typical use-case for doing this is comparing the current and subsequent years’ potential taxes. Or bonuses to be paid out to your employees in the next year.
It is important to note that the last record in the “NEXT_DATE” LEAD column will always be NULL, as there are no records in the next year/record.
Window Functions are not allowed in WHERE or GROUP BY clauses
As the subtitle suggests, “Window” functions are not allowed in WHERE or GROUP BY clauses. Let’s take a quick example to demonstrate this.
The syntax for the RANK function:
{SELECT id, date, customer_name, city, amount,
RANK() OVER(ORDER BY amount DESC) as amount_rank
FROM orders;We’re going to modify the above rank function we learned earlier, like so:
{SELECT id, date, customer_name, city, amount,
RANK() OVER(ORDER BY amount DESC) as amount_rank
FROM orders
WHERE amount_rank = 3;Alternatively, you can write the query like so:
{SELECT id, date, customer_name, city, amount
FROM orders
WHERE RANK() OVER(ORDER BY amount DESC) = 3;The above two queries demonstrate the changes made to replicate an error using Window functions in the WHERE clause.
{SELECT id, date, customer_name, city, amount,
ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) as rn
FROM orders
GROUP BY id, date, customer_name, city, amount, rn;The above query demonstrates the changes to replicate an error using Window functions in the GROUP BY clause.
WHERE Clause Error:
![]()
The above image is the error that Snowflake returns, essentially saying, window functions are not allowed in WHERE clauses.
The query seems pretty logical; we’re trying to find the rank of amounts and filter rank = 3. But Snowflake and all other databases/data warehouses don’t accept a window function in a where clause, returning a similar error as above.
GROUP BY Clause Error:
![]()
The above image is the error that Snowflake returns, essentially saying, window functions are not allowed in GROUP BY clauses.
The query seems pretty logical; we’re adding a new column, “rn,” that is essentially a pseudo-sequence. The result set is partitioned by city and reverse ordered by amount. But, Snowflake and all other databases/data warehouses don’t accept a window function in a group by clause, returning a similar error as above.
Why am I getting an error?
We get this error because SQL follows a logical order to execute operations. Here’s the order:
- From, Join
- Where Clause
- Group By Clause
- Aggregate Functions
- Having Clause
- Windows Functions
- Select
- Distinct
- Union/Intersect/Except
- Order By Clause
- Offset
- Limit/Fetch/Top
As you can see, the Windows functions fall well below the “Where” and “Group” by clauses. When the above query runs, we don’t have the Windows function to filter in the Where clause or Group by in the Group By clause—returning an error to the prompt.
Solution for Where Clause:
Use a Common Table Expression (CTE) to redefine your query and return the expected results set.
{WITH ranked_amount_query AS
(
SELECT id, date, customer_name, city, amount,
RANK() OVER(ORDER BY amount DESC) as amount_rank
FROM orders
)
SELECT id, date, customer_name, city, amount, amount_rank
FROM ranked_amount_query
WHERE amount_rank = 3;
The above child query first calculates the rank of the amounts as “amount_rank.” These ranks are then called from the main query with a filter on amount_rank = 3, thereby quickly helping us solve our requirement.
Solution for Where Clause:
Use a sub-query to redefine your query and return the expected results set.
{SELECT id, date, customer_name, city, amount, rn
FROM
(SELECT id, date, customer_name, city, amount,
ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) as rn
FROM orders) as rownumtable
GROUP BY id, date, customer_name, city, amount, rn;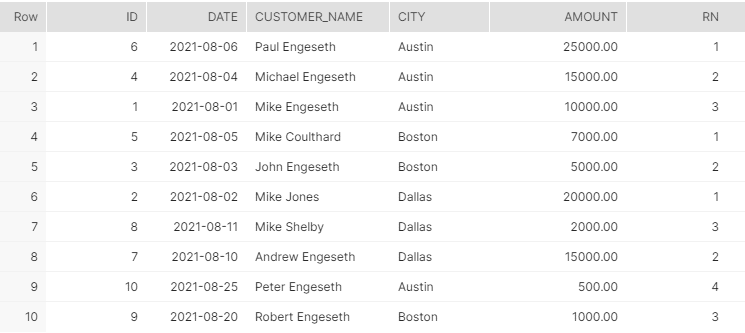
The above child query first calculates the row number partitioned by city, reverse ordered by amount, and displayed as “rn.” This is then called from the main query with a group by clause on all columns, thereby quickly helping us solve our requirement.
There you have it some of Snowflake SQL Window Functions and Common Errors.


