Remove Duplicate Records in Snowflake
- How-Tos FAQs
- September 7, 2020

Remove Duplicate Records in Snowflake
We will see two ways to remove duplicate data from Snowflake, depending on the kind of data that we have. Let’s begin by quickly creating some sample data within our Snowflake environment, as below:
But First… How Can Datameer Assist In Removal Of Duplicate Records In Snowflake
So we have seen how one can remove duplicate records directly in snowflake.
This was a bit long and could have been more efficient if we leveraged pre-built modeling tools like Datameer.
With Datameer, we could have used the graphical user interface dashboard to monitor our chain of transformations and prune out the duplicates without writing a single line of code.
Let’s put this in context.
See the video below.
In the video above, we leveraged Datameer’s low code approach to to identify those records where the value for column ‘id’ has a duplicate, using the ‘Aggregate’ feature, group by, and ‘Count’ in the measure to see the number of rows with each ‘id’.
--Using appropriate role to create objects
USE ROLE SYSADMIN;
--Create a new database TEST_1
CREATE OR REPLACE DATABASE TEST_1;
--Be sure to select database and its underlying default schema for use
USE DATABASE TEST_1;
USE SCHEMA PUBLIC;
--Create a new table Orders
CREATE OR REPLACE TABLE ORDERS
(
id NUMBER,
date DATE,
customer_name STRING,
city STRING,
amount NUMBER(10, 2)
);
--Insert sample records into Orders table
INSERT INTO orders
SELECT 1,'08/01/2021','Mike Engeseth','Austin',10000
UNION ALL
SELECT 2,'08/02/2021','Mike Jones','Dallas',20000
UNION ALL
SELECT 3,'08/03/2021','John Engeseth','Boston',5000
UNION ALL
SELECT 4,'08/04/2021','Michael Engeseth','Austin',15000
UNION ALL
SELECT 5,'08/05/2021','Mike Coulthard','Boston',7000
UNION ALL
SELECT 6,'08/06/2021','Paul Engeseth','Austin',25000
UNION ALL
SELECT 7,'08/10/2021','Andrew Engeseth','Dallas',15000
UNION ALL
SELECT 8,'08/11/2021','Mike Shelby','Dallas',2000
UNION ALL
SELECT 9,'08/20/2021','Robert Engeseth','Boston',1000
UNION ALL
SELECT 10,'08/25/2021','Peter Engeseth','Austin',500
;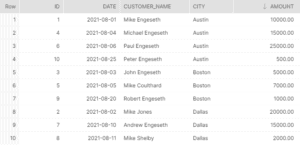
--View the data
SELECT *
FROM orders
ORDER BY city;The above code will create the required database and table, insert sample records into the table, and display a quick view of the inserted records.
The dataset is a sample set of product transactions within 3 cities in the United States by 10 unique customers on specific dates.
______________________________________________________________
Now, let’s introduce some duplicate data within the Orders dataset:
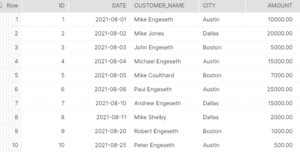
--View the data ordered by id
SELECT * FROM orders ORDER BY id;First, let’s view the dataset through a different lens, i.e., ordered by ‘id’ instead.
--Insert duplicate ids into the Orders table
INSERT INTO orders
SELECT 1,'04/01/2020','Cristiano Messi','Austin',100000
UNION ALL
SELECT 2,'03/02/2020','Lionel Ronaldo','Dallas',100000
UNION ALL
SELECT 3,'02/03/2020','Elon Gates','Boston',5000
UNION ALL
SELECT 4,'01/04/2020','Bill Musk','Austin',5000
;One quick note, Snowflake does not enforce constraints. For example, if you had marked ‘id’ as Primary Key, Snowflake would never enforce the uniqueness of said column and block duplicates from entering the table. Therefore, data duplication within Snowflake is a key activity.
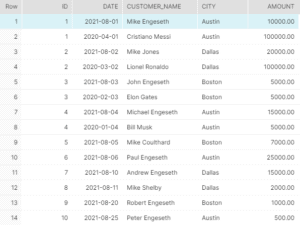
--View the data ordered by id
SELECT * FROM orders ORDER BY id;Since there are hardly any records, it might seem easy to work on this but imagine having millions of records and duplicates. It’d be hard to visualize without gathering simple metrics or descriptive statistics. But, that is a topic for another discussion.
______________________________________________________________
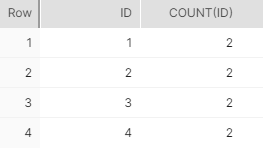
SELECT id, COUNT(id) FROM orders GROUP BY id HAVING COUNT(id) > 1;The above query helps identify those records where the value for column ‘id’ has a duplicate, i.e., duplicate id records. In our case, that is records 1 through 4.
This query is the standard way to identify duplicates through ANSI SQL and works on every database, including Snowflake.
We could repurpose the above query to remove the duplicates by adding the ‘DELETE FROM’ clause, like so:
DELETE FROM orders WHERE id in
(SELECT id FROM orders GROUP BY id HAVING COUNT(id) > 1);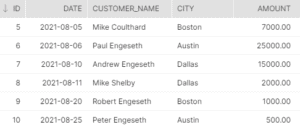
Please note, the query has removed the duplicate records but also the original records. This may not be the desired outcome. For this simple post, it is fine, but your use-case may vary significantly.
For example, you may want to retain the data but assign new ids to them, in which case the SELECT query to identify duplicates may be a good starting point.
Or you may want to remove the older set of duplicate records, in which case, you may want to either look at SCD (Slowly Changing Dimensions) or use the insert/last update date values of duplicate records from the table along with the SELECT query, as a potential starting point.
There may be several other use-cases, but the SELECT query is nevertheless a good starting point.
______________________________________________________________
With that said, let’s repopulate the table with duplicate records:
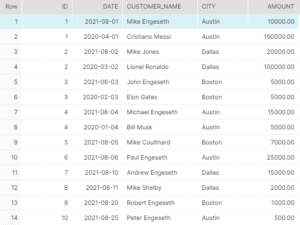
SELECT id, date, customer_name, city, amount,
ROW_NUMBER() OVER(PARTITION BY id ORDER BY id) rn
FROM orders ORDER BY id;Let’s calculate the rank of the id partitioned and ordered by id to display the following records:
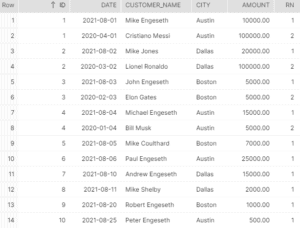
From the previous image, you’ll have noted that rank 2 signifies all of the duplicates.
It is now time to extract those duplicates, but we do this in a two-step process, as below:
CREATE OR REPLACE TABLE orders_new AS SELECT * FROM
(SELECT id, date, customer_name, city, amount,
ROW_NUMBER() OVER(PARTITION BY id ORDER BY id) rn
FROM orders ORDER BY id)
WHERE rn = 1;This changes the table structures:
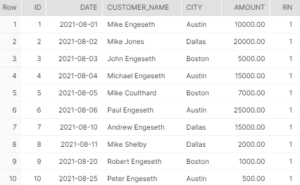
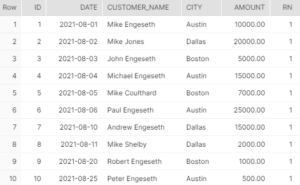
The orders_new table contains all the unique values or rank=1 records, while the orders table contains all the records but without the rank column.
ALTER TABLE orders SWAP WITH orders_new;With this powerful SWAP command, we simply interchange the table names, and our final ORDERS table has only the unique columns we require with no duplicate ids as below:
________________________________________________
Up Next:
Learn more about How to Generate a Series in Snowflake


