How to Handle Non-UTF-8 Characters in Snowflake
- How-Tos FAQs
- October 25, 2020

How to Handle Non-UTF-8 Characters in Snowflake
I’m currently working on a centralized social media platform that ultimately archives data in JSON format within Snowflake. These data come from various sources such as Twitter, Facebook, company website, and Instagram.
The one thing that has been challenging me for the past week is using non-UTF-8 characters in descriptive text. We had collectively chosen to ignore these special characters. Recently, my team and I have decided to analyze the special characters used widely within these social media platforms.
For this, we decided to simply isolate some of these characters within Snowflake using regular expressions. And then push this isolated data to the analytics black-box for those details I will not be able to share. However, the topic for this post is how to isolate those special character rows.
First, let’s create a few sample records that contain special characters intertwined with “correct” data:
For this, we are going to refer to w3 org’s list of special characters here. This is a simple post that helps to create and test some non-UTF-8 characters for us. Also, I’d like to give a shout-out to an online regular expression builder called “regex101” for helping in this particular use case.
--Using the appropriate context
USE ROLE SYSADMIN;
USE DATABASE TEST_1;
USE SCHEMA PUBLIC;Always make sure to use the appropriate context before beginning your work in Snowflake. I cannot stress this point enough.
--Creating the required table
CREATE OR REPLACE TABLE TEST_1.PUBLIC.Test
(CHECK_nonUTF8_DATA STRING);Let’s create the appropriate table that will hold our non-utf-8 data. Feel free to use a Temporary or Transient table depending on your requirement.
INSERT INTO TEST_1.PUBLIC.Test
SELECT 'Aμ' UNION ALL
SELECT 'LinguisticsAndDictionaries' UNION ALL
SELECT '�' UNION ALL
SELECT 'ăѣ𝔠ծềſģȟᎥ𝒋ǩľḿꞑȯ𝘱𝑞𝗋𝘴ȶ𝞄𝜈ψ𝒙𝘆𝚣1234567890!@#$%^&*()-_=+[{]};:,<.>/?' UNION ALL
SELECT '�����' UNION ALL
SELECT '߿' UNION ALL
SELECT '� � � � � � � � � � � � � � � � |
� � � � � � � � � � � � � � � �
'
;Now, we’re inserting the data into our table. In case you’re trying to use this data but unable to copy it correctly, here it is without any code block:
Aμ
LinguisticsAndDictionaries
�
ăѣ𝔠ծềſģȟᎥ𝒋ǩľḿꞑȯ𝘱𝑞𝗋𝘴ȶ𝞄𝜈ψ𝒙𝘆𝚣1234567890!@#$%^&*()-_=+[{]};:,<.>/?
�����
߿
� � � � � � � � � � � � � � � � |
� � � � � � � � � � � � � � � �
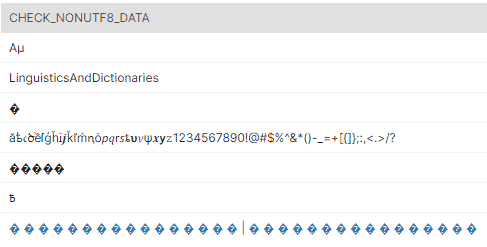
This is what the data looks like.
SELECT * FROM TEST_1.PUBLIC.Test
WHERE 1=1
AND NOT REGEXP_LIKE (CHECK_nonUTF8_DATA, '.*[^A-Za-z0-9].*');The idea is to eliminate all the characters in this column that aren’t in the English alphabet and remove all digits.
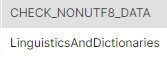
The result is a single record with “LinguisticsAndDictionaries.” Finally, we’ve got rid of all the records where special characters were present.

On the flip side, if we wanted the records that did have special characters in them, as in this image just above, we have to remove the “NOT” keyword from the REGEXP_LIKE where clause.
So, there you have it, a straightforward yet intuitive way to handle Non-UTF-8 characters in Snowflake by isolating your special characters within a dataset.